就在今天,路透社记者挖出了一个大瓜,原因让人瞠目结舌——
相比谷歌、微软等大厂,Meta跑AI时,用的竟然是CPU!
很难想象,在深度学习几乎占机器学习半壁江山的时代,一个科技巨头竟然能用CPU坚持这么久。
虽然他们也曾尝试过自研AI芯片,但最终遭遇滑铁卢。
现在,ChatGPT引爆的生成式AI大战打得昏天黑地,这就更加剧了Meta的产能紧缩。
Meta迟迟不肯接受用GPU的原因,令人匪夷所思。
GPU芯片非常适合AI处理,因为它们可以同时执行大量任务,从而减少处理数十亿条数据所需的时间。
然而,GPU 也比其他芯片更昂贵,英伟达控制着80%的市场份额,并在配套软件上,也保持着绝对的领先地位。
直到去年,Meta在处理AI工作负载时,主要使用的还是CPU。CPU是计算机的主力芯片,几十年来数据中心用的也是CPU,但它在AI工作上表现并不佳。
据悉,Meta还曾自研芯片,在内部设计的定制芯片上进行推理。
但在2021年,Meta还是失望地发现,比起GPU,这种双管齐下的方法速度更慢、效率更低。而且GPU在运行不同类型的模型上,远比Meta的芯片更灵活。
而且,小扎决定All In元宇宙这一举措,也直接榨干了Meta的算力。不管是AI的部署,还是威胁的应对上,都遭到了极大的削弱。
这些失误,引起了前Meta董事会成员Peter Thiel的注意,随后,他于2022年初辞职。
据内部人士透露,在离开前的一次董事会会议上,Thiel告诉小扎和高管们,他们对Meta的社交媒体业务太自满,并且过分关注元宇宙了,这让公司很容易被TikTok的挑战所撼动。
Meta粗大事了
在去年夏天快要结束的时候,小扎曾召集了高级副手们,花了五个小时,对Meta的计算能力进行分析。
他们需要知道,在开发尖端的AI方面,Meta有多大的能力?
根据9月20日的公司备忘录显示,尽管Meta对AI研究进行了大笔高调的投资,然而主要业务需要的AI友好型硬件和软件系统都非常昂贵,在这些方面公司的进展相当缓慢。
这可是个棘手的大麻烦,要知道,Meta的增长,越来越依赖AI。
基础设施负责人Santosh Janardhan强调,无论是开发AI的工具,还是工作流程,Meta都已经远远落后于其他对手。
「Meta需要从根本上改变物理基础设施设计、软件系统和提供稳定平台的方法。」
一年多来,Meta一直在搞的大项目,就是希望完善AI基础设施。但经历过产能紧缩、领导层变动和废弃的AI芯片项目后,Meta的改革似乎不尽如人意。
对于外媒的这个提问,Meta发言人Jon Carvill表示,公司「在大规模创建和部署最先进的基础设施方面有着良好的记录,并有着人工智能研究和工程方面的深厚专业知识。」
「随着我们为应用程序和消费产品系列带来新的AI体验,我们有信心继续扩展基础设施的能力,以满足我们的近期和长期需求。」
据悉,改革使Meta每季度的资本支出增加了约40亿美元,几乎是2021年支出的两倍。而且Meta此前建设4个数据中心的计划,也因此暂停或取消。
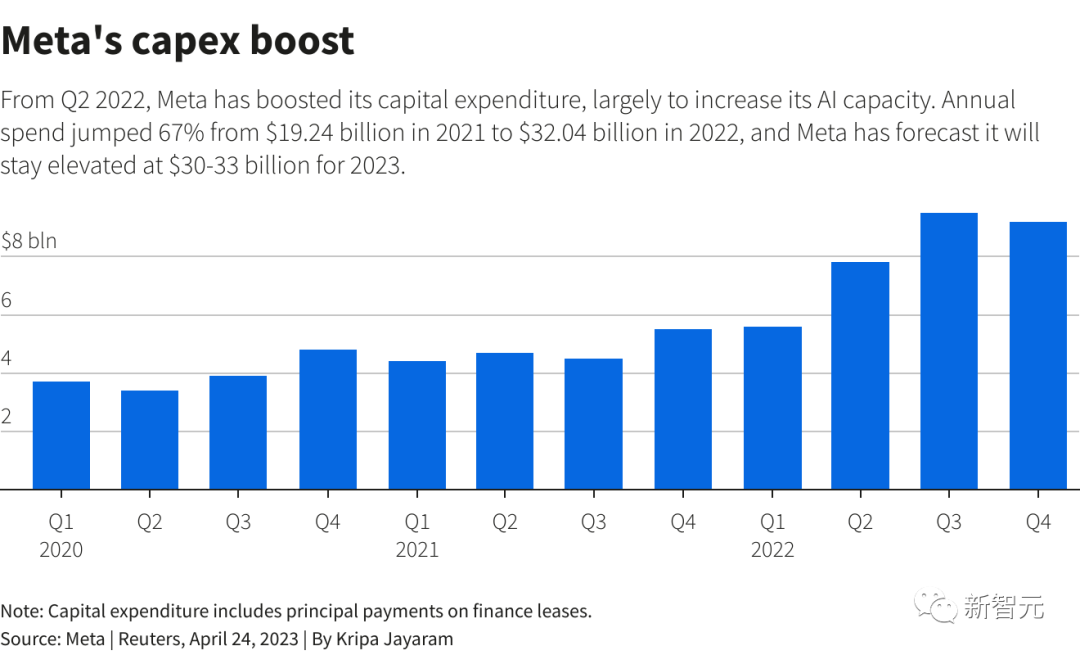
而这些大笔支出,跟Meta严重的财务紧缩期又恰恰重合。
去年11月以来,硅谷的互联网泡沫开始破灭,Meta一直在大规模裁员。
OpenAI的ChatGPT在11月30日亮相后,立马引爆了科技巨头之间的军备竞赛。
此后的生成式AI大战,吞噬了大量的算力,这更逼得Meta加紧改革。
极力追赶
高管们取消了在2022年大规模推出自研芯片的计划,转头订购了价值数十亿美元的英伟达GPU。
Meta已经落后于谷歌等同行一大截,谷歌早在2015年就开始部署自己定制的GPU——TPU。
在2022年春天,高管们也同时开始着手重组Meta的AI部门。
这期间发生了长达数月的动荡,十几位高管离开了。AI基础设施领导层,整个经历了一次大换血。
他们得费老大劲重组数据中心,来适应新的GPU,因为GPU比CPU的功耗和产热都更多,还必须用专用网络把它们聚在一起。
为了管理集群的热量,这些设施需要24到32倍的网络容量和新的液冷系统,因此需要从头设计。
即便如此,Meta似乎也并没有放弃自研芯片的路线。
据悉,新的内部芯片会和GPU一样,能够训练AI模型并执行推理,将于2025年左右完成。
悬崖勒马,回头是岸
此前,微软有ChatGPT,谷歌紧忙拉Bard出来对打,Meta却似乎并不急于下场生成式AI竞赛,推出的LLaMA也并不用作商用。
Meta CFO Susan Li在2月承认,Meta并没有将大部分计算资源投入到生成式AI中,而是基本上将所有的AI能力都用于广告、feeds和Reels(类似于TikTok的短视频)。
此前,同谷歌一样,Meta并不重视生成式AI。Meta的FAIR实验室从21年底以来,就在发布这种AI技术的原型,研究成果也备受推崇,但Meta从未考虑过将其转化为产品。

去年11月中旬,Meta的FAIR实验室曾提出Galactica模型
然而ChatGPT诞生后,一切都不一样了。投资者的兴趣开始飙升,小扎在今年二月官宣了全新的顶级团队,押宝生成式AI。
据悉,工作的重点是建成一个基础模型,在这个核心的基础上,可以针对不同产品进行微调和调整。
18个月前,小扎把Facebook的未来押在了元宇宙上,甚至还把公司的名字改成了Meta。最近,他又迷上了另一个非常烧钱的技术——AIGC。
本月早些时候,Meta首席技术官Andrew Bosworth表示,扎克伯格和其他高管现在把大部分时间都花在了人工智能上。
对此,Bernstein的分析师表示,照这个架势下去,Meta很可能要改名叫——MetAI了。
不过,想要追上OpenAI、微软和谷歌的步伐,Meta就必须为训练这些超大规模的生成式AI模型,大肆采购英伟达的芯片(单个组件1万美金起跳)。
目前,耗时5个月训练出的「Meta版ChatGPT」LLaMa,用的是2048个80GB显存的A100。
作为对比,微软为OpenAI量身定做的超算,搭载的可是上万块A100。
而ChatGPT和Bard「决一死战」的背后,正是英伟达CUDA支持的GPU(图形处理单元)和谷歌定制的TPU(张量处理单元)。
换句话说,这已经不再是关于ChatGPT与Bard的对抗,而是TPU与GPU之间的对决,以及它们如何有效地进行矩阵乘法。
由于在硬件架构方面的出色设计,英伟达的GPU非常适合矩阵乘法任务——能有效地在多个CUDA核心之间实现并行处理。
因此从2012年开始,在GPU上训练模型便成为了深度学习领域的共识,至今都未曾改变。
而随着NVIDIA DGX的推出,英伟达能够为几乎所有的AI任务提供一站式硬件和软件解决方案,这是竞争对手由于缺乏知识产权而无法提供的。
相比之下,谷歌则在2016年推出了第一代张量处理单元(TPU),其中不仅包含了专门为张量计算优化的定制ASIC(专用集成电路),并且还针对自家的TensorFlow框架进行了优化。
而这也让TPU在矩阵乘法之外的其他AI计算任务中具有优势,甚至还可以加速微调和推理任务。
不过,微软与英伟达长久以来的深度合作,让各自在行业上的积累得到充分地利用,并以此同时扩大了双方的竞争优势。
尤其是当ChatGPT开始横扫整个AI圈时,两家公司的市值也是一路狂飙。
而这波被ChatGPT带起来的大模型炼丹潮,更是让「炼丹炉」供应商英伟达赚得盆满钵满。仅在今年的这几个月里,市值就增长了超过80%。
然而,Meta现在好像并没有足够的资金来支撑自己的野心。
众所周知,这段时间裁员潮继续席卷了整个科技行业,但有些公司裁得比别人更多。
在比例上,裁掉80%员工的推特毫无疑问地占据了第一的位置,而送走近四分之一员工的Meta紧随其后。
在数量上,Meta也凭借着高达2.1万人的巨大优势位列第二,但这并没包括即将进行第三轮裁员。
2022年,在小扎宣布大裁员之前,Meta有差不多87,000名员工。但在11月时毕业了11,000人,3月又毕业了10,000人。
据Insider报道,Meta的第三轮裁员会直接影响数千人,而管理层职位更是首当其冲。包括但不限于,现实实验室、Facebook和Instagram的技术产品经理,以及人工智能研究科学家、软件工程师、数据工程师等。
最新的一项分析显示,从2018年到2022年,Meta的员工队伍膨胀了143%,但每个员工的收入在这段时间内下降了14%。
高管变动、员工流失、资金不足、路线选错,Meta前方的路,似乎困难重重。

 新智元 · 2023年04月26日
新智元 · 2023年04月26日


































